Category
Description
This repository contains data for the experiments run in the paper "Understanding Generative AI Content with Embedding Models" (https://arxiv.org/abs/2408.10437).
DataBase POC: Max Vargas (max.vargas@pnnl.gov)
The data is separated by experiment:
A. The `stack_exchange` dataset contains a collection of stack exchange queries, along with user-posted answers and responses generated by three different large language models (LLMs). The LLMs used were Llama-2 70B (https://huggingface.co/meta-llama/Llama-2-70b-chat-hf), Mixtral 8x7B (https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1), and Falcon 40B (https://huggingface.co/tiiuae/falcon-40b-instruct) and the queries can be found at https://huggingface.co/datasets/lvwerra/stack-exchange-paired.
B. The `translations` data is split into three sub-directories.
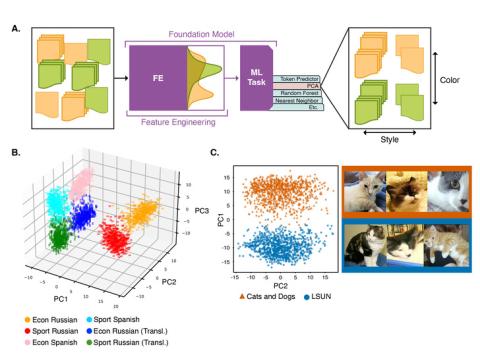
i. The `cross_lingual` directory contains Sports and Economics news articles translated across different languages using the nllb-200-distilled-600M (https://huggingface.co/facebook/nllb-200-distilled-600M) language model. The news articles are sourced from the MLSUM dataset (https://huggingface.co/datasets/reciTAL/mlsum).
ii. The `german_sport_5k` directory contains German Sport articles from the MLSUM dataset that have been translated to English using nllb-200-distilled-600M, nllb-200-3.3B (https://huggingface.co/facebook/nllb-200-3.3B), Opus (https://huggingface.co/Helsinki-NLP/opus-mt-de-en), Mistral 7B (https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1), and Mixtral 8x7B.
iii. The `unpc` directory contains test samples from the UNPC dataset (https://conferences.unite.un.org/uncorpus) that have been translated by three different language models; nllb-200-3.3B, Opus, and Llama-2 70B.
C. The `cat_images` directory contains real sample images of cats from various datasets (LSUN https://arxiv.org/abs/1506.03365 and Cats Vs. Dogs https://www.tensorflow.org/datasets/catalog/cats_vs_dogs). It also contains images that were generated by generative AI models. The models used are a Denoising Diffusion Probabilistic Model (https://huggingface.co/google/ddpm-cat-256), Stable Diffusion XL (https://openreview.net/forum?id=di52zR8xgf), and Open Dalle (https://huggingface.co/dataautogpt3/OpenDalleV1.1). For the text-conditional models, we include prompts used to generate images.
D. The `abstracts` directory contains samples of https://arxiv.org/ abstracts from the categories given by subject codes `hep-ex`, `cs.PL`, `q-bio.CB`, `stat.ME`, `q-fin.PM`, and `econ.GN`. The data also contains synthetic abstracts generated using Llama-2 70B.
E. The `gen_image_benchmark` data contains sampled classes and categories from the corresponding GenImage (https://genimage-dataset.github.io/) benchmark dataset for AI-detection.
This work was partially supported by the Statistical Inference Generates kNowledge for Artificial Learners (SIGNAL) program at PNNL. This work was also supported, in part, by the Office of Defense Nuclear Nonproliferation Research and Development within the U.S. Department of Energy’s National Nuclear Security Administration and Pacific Northwest National Laboratory, which is operated by Battelle Memorial Institute for the U.S. Department of Energy under contract DE-AC05-76RL01830.