Publication
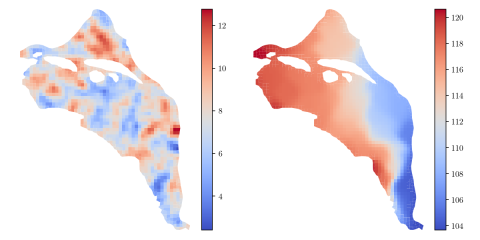
A major challenge in biotechnology and biomanufacturing is the identification of a set of biomarkers for perturbations and metabolites of interest. Here, we develop a data-driven, transcriptome-wide approach to rank perturbation-inducible genes from time-series RNA sequencing data for the discovery...